
Kunstmatige intelligentie (AI) speelt in de cultuur- en erfgoedsector een steeds belangrijkere rol. AI geeft legio mogelijkheden om collecties te analyseren, contextualiseren, presenteren en meer. Maar heeft AI ook iets met Linked Data te maken? En wat gebeurt er eigenlijk concreet met AI bij erfgoedinstellingen? Maar liefst vijf onderzoekers en ontwikkelaars hebben ons hierover bijgepraat op 21 mei.
Beschouwende inleiding op het vakgebied AI – door Cynthia Liem (TU Delft)
De inzet van Linked Data technologie speelt een grote rol in de strategie om de zeer versnipperde wereld van erfgoedinformatie beter vindbaar te maken. Door de vele aandacht voor AI lijkt soms de indruk te ontstaan dat AI vooral een opvolger is van Linked Data / Knowledge Engineering. Maar is AI daadwerkelijk een vervanging, of complementeren AI en kennis elkaar juist?
Biografie: Cynthia is Universitair Docent aan de Multimedia Computing Group aan de TU Delft, professioneel musicus, en lid van De Jonge Akademie. Haar werk richt zich op betrouwbare en verantwoorde AI-inzet, waarbij ze technieken voor automatische inhoudsbeschrijving, filtering, aanbeveling en validatie probeert in te zetten, om een verbreding van perspectieven te stimuleren. Hierbij zet ze zich met name in om “datgene wat we niet triviaal zien en al weten” binnen handbereik te houden.
Interessantheid van kunst-relaties inschatten via Wikidata – door Simon Dirks (master-student AI, Universiteit Utrecht)
Eerder gaf Simon ons al een introductie over zijn masterscriptie, een onderzoek naar het via Wikidata automatisch vinden van kunst-relaties. Bijvoorbeeld: “deze schilderijen zijn beide gemaakt door een dove kunstenaar”. Inmiddels hebben 320 mensen geholpen met het beoordelen van 136 kunst-relaties op interessantheid (waarvoor dank!), en heeft Simon een vuistregel gedefinieerd om via Wikidata een schatting te maken van hoe interessant men een gegeven kunst-relatie vindt. Nu deelt Simon in een pre-recording voor de sessie op Youtube zijn (voorlopige) resultaten, het proces ernaartoe, ideeën voor verbeteringen, en meer!
Biografie: Simon is een 24-jarige Kunstmatige Intelligentie, bijna afgestudeerde, master-student met een passie voor de overlap tussen informatica en cultuur. Momenteel is hij deel van de Utrecht Time Machine, en sinds kort co-docent informatica. Met een achtergrond in game- en software-ontwikkeling en een eigen bedrijf voor het maken van geanimeerde video’s, lijkt de rode draad vooral “maken!” te zijn.
Demosaurus – door Thomas Haighton (Koninklijke Bibliotheek, KB)
Thomas gaf een presentatie over de tool die de KB aan het ontwikkelen is. De tool heet Demosaurus en is gemaakt om catalogiseerders bij te staan. De tool suggereert a.d.h.v. aangeleverde metadata wat de best passende (Brinkman / CBK) onderwerpen zijn en welke personen verbonden zijn aan de ingevoerde publicatie. De kracht van de software zit in het gebruik van machine learning algoritmes, deze zijn getraind met data uit het GGC (gezamenlijke catalogiseer omgeving voor bibliotheken).
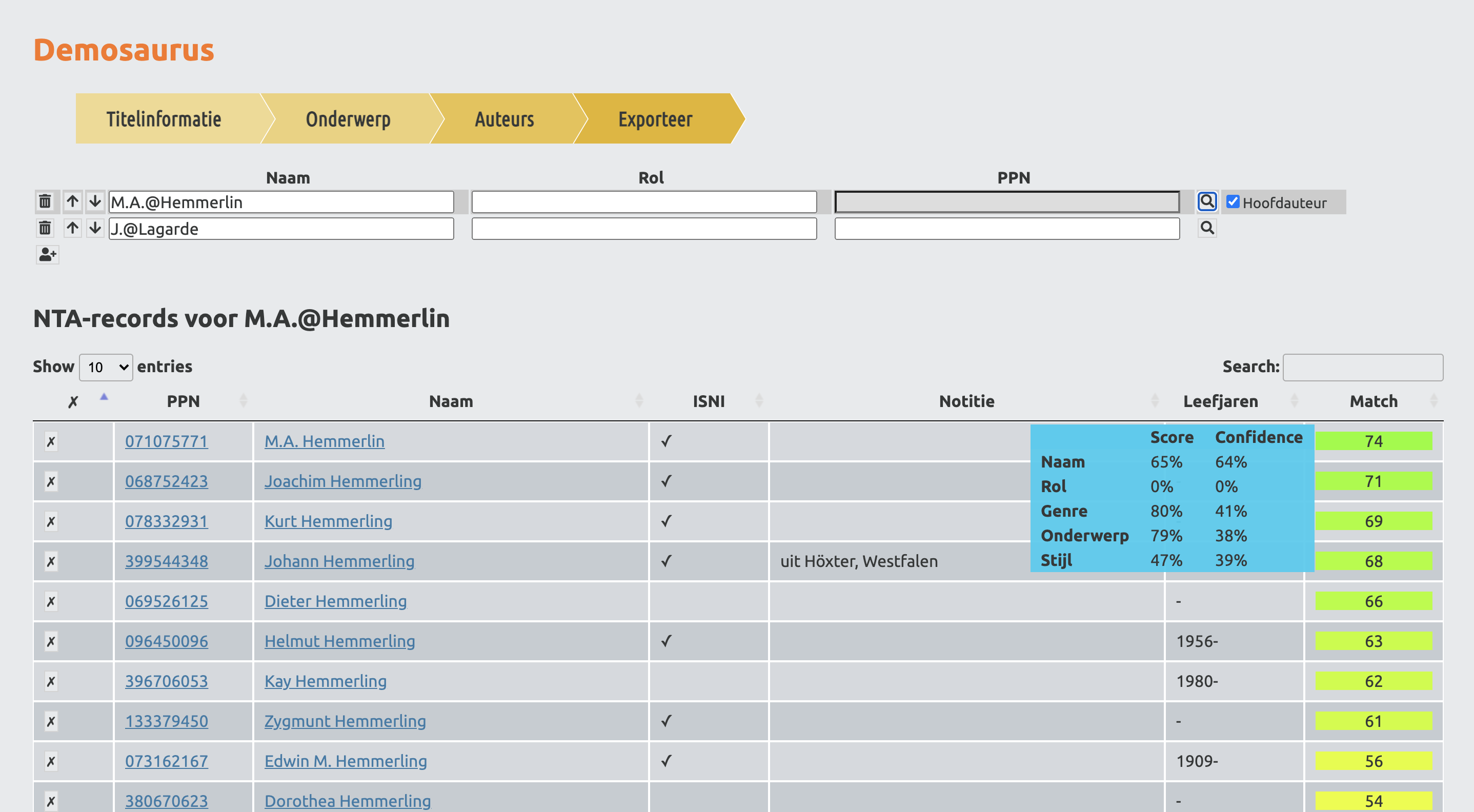
Biografie: Thomas werkt bij de KB als Metadataspecialist op de afdeling Digitalisering. Hier houdt hij zich voornamelijk bezig met de kwaliteit van aangeleverde metadata van gedigitaliseerd materiaal, en participeert hij in verschillende interne onderzoeksgroepen die zich bezig houden met AI. Het laatste half jaar kon Thomas als onderzoeksprogrammeur zich volledig bezighouden met de doorontwikkeling van de Demosaurus.
Named Entity Recognition en Named Entity Linking – door Rana Klein (Beeld en Geluid)
Hoewel het voor mensen kinderlijk eenvoudig is om persoonsnamen, plaatsen en namen van organisaties uit een tekst te extraheren is het erg tijdrovend om dit te doen voor een volledig archief. Een goede reden om dit uit te besteden aan een computer! Hoe kan Machine Learning hierbij helpen? Tegen welke problemen loopt AI aan? Het uiteindelijke doel: Met één druk op de knop alle genoemde entiteiten uit een tekst of video transcriptie extraheren, en linken aan de daarbij horende (Wikidata) identifiers voor meer achtergrond en context.
Biografie: Rana is werkzaam als AI Developer voor Beeld en Geluid. Ze ontwikkelt Machine Learning Modellen, Pipelines en Benchmarking Tools. Hoewel Rana door haar master Logica een fundamentele filosofische en wiskundige achtergrond heeft staan voor haar de wensen van de gebruiker voorop.
Gebruik van AI bij historisch onderzoek – door Gerhard de Kok (Universiteit Leiden / Internationaal Instituut voor Sociale Geschiedenis)
Gerhard de Kok is historicus en zet voor zijn onderzoek AI en andere digitale technieken in. Vooral door de inzet van HTR-transcripties voor enkele grote archieven, is zijn interesse in nieuwe onderzoeksmethodes gewekt. Gerhards experimenten van afgelopen tijd betreffen vooral de inzet van NLP voor historisch onderzoek, een gebied waar linguïsten een grote voorsprong hebben op historici.
Biografie: Gerhard doet onderzoek en geeft les aan de Universiteit Leiden en het Internationaal Instituut voor Sociale Geschiedenis (IISG). Zijn focus ligt op de Nederlandse maritieme connecties met de koloniale wereld. In 2019 verkreeg hij zijn PhD met een thesis over lokale economische effecten van de Nederlandse deelname aan de trans-Atlantische slavenhandel.







{kind=link}